Functional Programming...continued
Every function that you typically write has two sets of inputs and two sets of outputs, and we're not talking about a count of the parameters.
That's a little confusing right?
So how did I arrive two input and two outputs?
Let's take a look at the first pair of inputs:
Code:
func square(x: Int) -> Int
{
return x * x
}
NOTE: The language doesn't matter, but I've picked Swift, considering that's the premise of this thread; as this would apply to any language with explicit input & output types, for example: Java, C#, ....
Here the input you're used to thinking about is
x is a Int, and the output of the function is also something you're also used to: it returns an
Int. That's the first set of inputs & outputs.
The obvious set. Now let's see an example of the second set of inputs and outputs:
Code:
func processNext()
{
guard let message = InboxQueue.popMessage() else { return }
process(message)
}
According to the syntax,
this function appears to take no inputs and returns no output, and yet it's obviously dependant on something, and it's obviously doing something. It has a
hidden set of inputs and outputs. The hidden input is the state of the InboxQueue before the popMessage() call, and the hidden outputs are whatever process does, plus the state of InboxQueue after this function completes. The state of InboxQueue is the input of this function. The behaviour of processNext is unknown without knowing that value. And it's output is a mystery too; the result of calling processNext can't easily be understood without considering the state of InboxQueue, or what it actually does.
So the second piece of code has
hidden inputs and outputs. It requires things, causes things and affects things, but you could never guess what just by looking at the API, or even at this function.
This design is the very antithesis of Functional Programming.
The official name for hidden inputs and outputs is "side-effects", but we should probably think of this as two things:
- "side-effects" for the hidden outputs and effects,
- "indeterminate state" for the hidden inputs.
For the rest of this post and for simplicity; I'll just use "side-effects", but you should remember that it covers both these scenarios.
Side-Effects are like Icebergs.
[table="width: 600"]
[tr]
[td]
[/td]
[td]
the top gives you a false impression of simplicity, all the while it hides its shear complexity under the water[/td]
[/tr]
[/table]
When functions have side-effects, you can look at a function like this:
Code:
func processMessage()
{
channel.popMessage()
channel.processMessage()
}
…and just when you think you've got an idea of what it's doing, you end up being totally wrong. There's just no way to know what it requires or what it will do without looking inside.
- Does it take a message off the channel and process it? Probably.
- Does it close your channel if some condition is true? Maybe.
- Does it update a count in the database somewhere? Perhaps.
- Does it explode if it can't find the logging directory path it was expecting? It might.
When coupled with Cowboy Refactoring, this turns into a veritable spaghetti code experience, following one function to a class, to another function which leads to only more and more hidden complexity...
Aaah... this is about the time I want to pull my hair out.
[table="width: 500"]
[tr]
[td]

[/td]
[/tr]
[/table]
Beneath the surface of this API is a potentially vast block of extra complexity.
To grasp it, you'll only have three options:
- dive down into the function definition
- bring the complexity to the surface,
- or ignore it and hope for the best.
And in the end, ignoring it is usually a titanic mistake.
Revelling in the complexity of object graphs
Wow you should see the object graph of the project I am working on; it's UML diagram is huge... blah.... blah...
[table="width: 500"]
[tr]
[td="width: 200"]
[/td]
[td]Many people when shown a mathematical formula, almost instantly get this glassy-eyed look about them, followed by a subtle Yawn. Almost as if their mind had unwillingly shifted them into neutral: the engine's on, but the wheels ain't turning.

[/td]
[/tr]
[/table]
As I'm sure you've realised I don't like this style of programming too much; call it the bad side of OOP. OOP has many positive aspects and I use it frequently in my code, however I not a big fan of hidden complexity.
Why you ask?
It's kind of simple; my brain never get the opportunity to shift into neutral until I'm already pulling my hair out. Cognitively it's a mess and certainly nothing to boast about. With Functional Programming the complexity is immediately visible, hence my brain can choose to shift to neutral or not.
Pragmatically this style of OOP is a problem because:
- It's untestable; can you really be sure you've covered all the eventualities?
- It's new age spaghetti code; it was never popular in the 70s or 80s, so why does it now make sense.
- It's difficult to train; it's a huge hurdle when new developers join your team, and even worse when you hand over to maintenance.
- It's breaks easily; for most of the same reasons it's difficult to test.
- It's a pain in the derrière to multi thread.
- .... I could go on, but that would just be me venting...
Now do yourself a favour and go back and look at the first function example in this post; do you immediately understand what it does, where it gets it's input and what output it would return? Yes, this is the essence of Functional Programming:
To create functions that are designed simply: specifically avoiding mutable state, hidden inputs and outputs (side-effects), so your brain can easily make a choice
So final question; if Functional Programming is better than OOP, why does OOP still need to exist?
Well for one you can't design certain aspects of an application without mutable state, for example: UI (user interfaces), NIC (network interface controller), ... are examples of indeterminate mutable state; meaning you need a way to model events, changing states, etc. but that doesn't mean the entire system needs to mutable; hence the drive towards extended language support for Functional Programming.
In my experience the ratios of OOP vs FP in your application will vary, however I typically find that most of the object graph is better modelled as immutable state (FP) i.e. I tend to challenge why something needs to maintain mutability instead of the other way around.
Next post: I'll look at comparing this in a few popular languages, and as I said I'm might even tackle a before and after scenario (assuming I can find a simple enough one)
















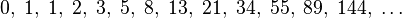
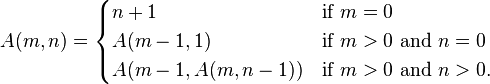



")