

Yeah inpainting. I've spent the last 3 days in blender, my brain is a bit fried.You're probably thinking of inpainting. High res? Not really unless you have a beast of a GPU. Invoke AI is probably the best for your requirement, though it seems they're starting to introduce different tiers of the products and most of them paid. I haven't used it in a while, but it had a one click installer that mostly worked without too much hassle.
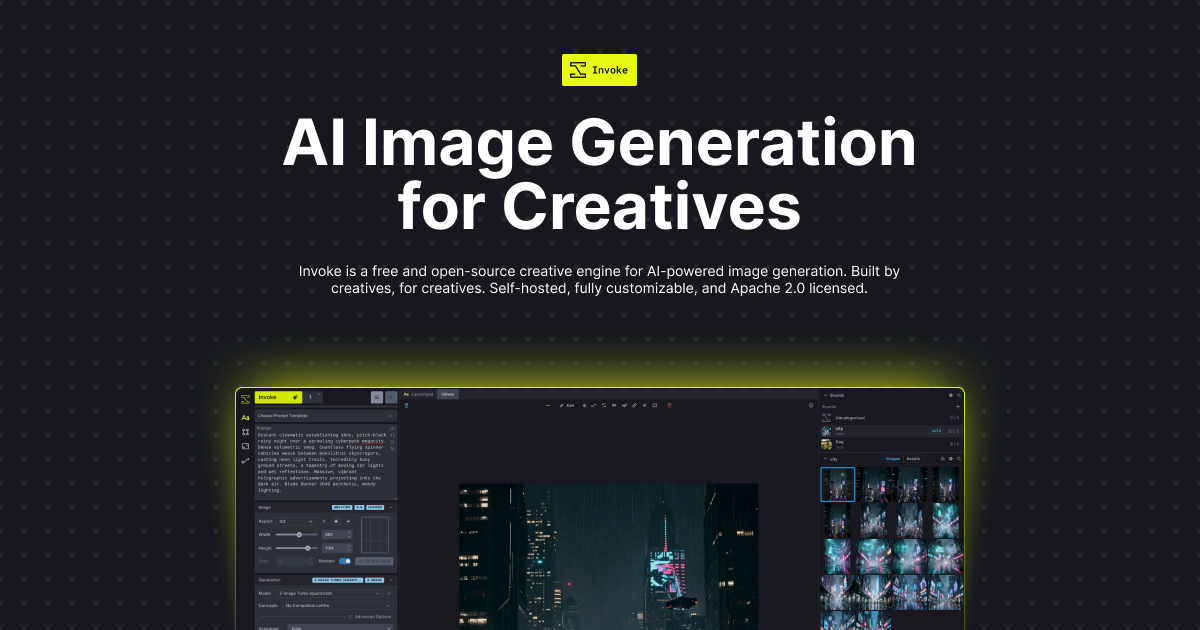
AI Image Generation for Creatives
A leading creative engine built to empower professionals and enthusiasts alike.invoke.ai
-
- News
-
Categories
- 5G
- ADSL
- AI
- Banking
- Black Friday
- Broadband
- Broadcasting
- Business
- Business Telecoms
- Cellular
- Cloud and Hosting
- Columns
- Cryptocurrency
- Energy
- Enterprise
- Fibre
- Gadgets
- Gaming
- Government
- Hardware
- Industry News
- Internet
- Internet of Things
- Investing
- IT Services
- Motoring
- Reviews
- Science
- Security
- Smartphones
- Software
- Technology
- Telecoms
- Trending
- Wireless
- Press Office
- Forum
- Industry News
- What's Next
- Company hub
- Speed Test
- About us
- Advertise with us
- Contact
- Careers
-
Join the MyBroadband community
South Africa’s biggest forum. Discuss, discover, and connect with thousands of members.
-
Question of the Day: Do you think you could pass a driver's licence test without any preparation?
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Stable Diffusion AI Image Generator
- Thread starter OnlyOneKenobi
- Start date
shaggy_beef_on_a_tricycle
Well-Known Member
Photoshop to be honest. Best in the industry.Which route to get an offline image infill tool - the kind where you select a region and have it add whatever you prompted? Forgot whether this is native to SD...haven't opened it in ages. Also can offline tools handle working directly with higher res images - 2160*1440 etc?
Would prefer a simple install...cba messing around with python again.
Stable Diffusion can work, but it is not a simple installation and method. It is free though.
OnlyOneKenobi
Executive Member
- Joined
- Dec 6, 2013
- Messages
- 5,348
- Reaction score
- 7,960
Hmmm. Photoshop generative fill is cool but it's not quite the same as inpainting.Photoshop to be honest. Best in the industry.
Stable Diffusion can work, but it is not a simple installation and method. It is free though.
shaggy_beef_on_a_tricycle
Well-Known Member
Then use Content-Aware FillHmmm. Photoshop generative fill is cool but it's not quite the same as inpainting.
OnlyOneKenobi
Executive Member
- Joined
- Dec 6, 2013
- Messages
- 5,348
- Reaction score
- 7,960
Haha... Also not really the same. Both have their merits though but SD is more flexible in what you can achieve. Photoshop will just plonk whatever you what it thinks you want, based on your prompt while inpainting has influence over what you can generate to varying degrees, combine that with a prompt and your result would be closer to what you envisioned.Then use Content-Aware Fill
shaggy_beef_on_a_tricycle
Well-Known Member
Whatever your IA desires.Haha... Also not really the same. Both have their merits though but SD is more flexible in what you can achieve. Photoshop will just plonk whatever you what it thinks you want, based on your prompt while inpainting has influence over what you can generate to varying degrees, combine that with a prompt and your result would be closer to what you envisioned.
OnlyOneKenobi
Executive Member
- Joined
- Dec 6, 2013
- Messages
- 5,348
- Reaction score
- 7,960
In a nutshell, (thanks CHATGPT) : In summary, Adobe Photoshop’s Generative Fill is deeply integrated into the Photoshop environment, providing a seamless experience for adding, removing, or altering content with text prompts and layer-based editing. In contrast, Stable Diffusion’s Inpainting is more focused on altering specific areas of an image, leveraging AI models specially designed for this purpose, and providing a range of settings to control the extent and style of changes made to the image.
OnlyOneKenobi
Executive Member
- Joined
- Dec 6, 2013
- Messages
- 5,348
- Reaction score
- 7,960
I still can't get over how crazy powerful this tech is. As an exercise to see what a character might have looked like, if it wasn't necessary to cast a different actor in the role, I took the original Obi-Wan \ Ben Kenobi as an example.
Using a publicity still of Ewan McGregor's Obi-Wan for the pose, I first used the IP Adapter to get the proportions of Alec Guiness' head, facial features and hairline correct, then face swapped Alec Guiness' face into the shot (SD wouldn't draw the face correctly), then de-aged him using Stable Diffusion and then inpainted the full beard - and this is the result. Interesting that there is still some resemblance to McGregor despite the face being completely changed in the earlier steps. I guess the casting was pretty good!

The original images :


Using a publicity still of Ewan McGregor's Obi-Wan for the pose, I first used the IP Adapter to get the proportions of Alec Guiness' head, facial features and hairline correct, then face swapped Alec Guiness' face into the shot (SD wouldn't draw the face correctly), then de-aged him using Stable Diffusion and then inpainted the full beard - and this is the result. Interesting that there is still some resemblance to McGregor despite the face being completely changed in the earlier steps. I guess the casting was pretty good!
The original images :
So I'm using chaiNNer for upscaling - works ok, the interface is nice and the install is simple. Is there a similar local tool that can also improve image quality, do some denoising etc? I sometimes get a scan of a graphic I need to use in a render and aside from the upscale it would really help to get it looking as clear as possible.

OnlyOneKenobi
Executive Member
- Joined
- Dec 6, 2013
- Messages
- 5,348
- Reaction score
- 7,960
You can just use the various upscalers within stable diffusion, "Extras" in Automatic1111. Not sure exactly where they're found in Invoke, but they're there somewhere. You can download specialised models for different purposes, and most likely use them in chaiNNer too if you prefer using them there.So I'm using chaiNNer for upscaling - works ok, the interface is nice and the install is simple. Is there a similar local tool that can also improve image quality, do some denoising etc? I sometimes get a scan of a graphic I need to use in a render and aside from the upscale it would really help to get it looking as clear as possible.
View attachment 1626965
https://openmodeldb.info/
I typically use 8x_NMKD-Superscale_150000_G for photorealistic upscales and 4x-UltraSharp for concept art, digital paintings, cgi style. There are many other models ranging from anime, to photoreal, to lineart, etc, etc, etc.
Yeah that works in chainner thx. Didn't realize I could load other models.You can just use the various upscalers within stable diffusion, "Extras" in Automatic1111. Not sure exactly where they're found in Invoke, but they're there somewhere. You can download specialised models for different purposes, and most likely use them in chaiNNer too if you prefer using them there.
https://openmodeldb.info/
I typically use 8x_NMKD-Superscale_150000_G for photorealistic upscales and 4x-UltraSharp for concept art, digital paintings, cgi style. There are many other models ranging from anime, to photoreal, to lineart, etc, etc, etc.
shaggy_beef_on_a_tricycle
Well-Known Member
Now combine it with Tile VAE and COntrolNET and you can go crazy on details.Yeah that works in chainner thx. Didn't realize I could load other models.
GitHub - pkuliyi2015/multidiffusion-upscaler-for-automatic1111: Tiled Diffusion and VAE optimize, licensed under CC BY-NC-SA 4.0
Tiled Diffusion and VAE optimize, licensed under CC BY-NC-SA 4.0 - pkuliyi2015/multidiffusion-upscaler-for-automatic1111
 github.com
github.com
OnlyOneKenobi
Executive Member
- Joined
- Dec 6, 2013
- Messages
- 5,348
- Reaction score
- 7,960
Do you use Tiled VAE? It is powerful, but I find it difficult to use and somewhat unpredictable. As far as I have seen, each image requires a lot of experimentation to find the correct settings to get it upscaled just right. Maybe I'm just doing it wrong, but I do have a few other upscaling tricks up my sleeves at least.Now combine it with Tile VAE and COntrolNET and you can go crazy on details.

GitHub - pkuliyi2015/multidiffusion-upscaler-for-automatic1111: Tiled Diffusion and VAE optimize, licensed under CC BY-NC-SA 4.0
Tiled Diffusion and VAE optimize, licensed under CC BY-NC-SA 4.0 - pkuliyi2015/multidiffusion-upscaler-for-automatic1111
shaggy_beef_on_a_tricycle
Well-Known Member
Hit and miss to be honest. But helps me with my 1070 which cant handle much.Do you use Tiled VAE? It is powerful, but I find it difficult to use and somewhat unpredictable. As far as I have seen, each image requires a lot of experimentation to find the correct settings to get it upscaled just right. Maybe I'm just doing it wrong, but I do have a few other upscaling tricks up my sleeves at least.
Now try mess around with LCM LoRA. Works nice on cartoon characters:

LCM-LoRA: High-speed Stable Diffusion - Stable Diffusion Art
LCM-LoRA can speed up any Stable Diffusion models. It can be used with the Stable Diffusion XL model to generate a 1024x1024 image in as few as 4 steps.
 stable-diffusion-art.com
stable-diffusion-art.com
OnlyOneKenobi
Executive Member
- Joined
- Dec 6, 2013
- Messages
- 5,348
- Reaction score
- 7,960
What works well (in my experience), is to use highres fix to upscale from the initial generation, then you send your image to "extras", upscale it there 2x, send it to inpaint, add some more details via inpainting (inpaint masked areas only) in various sections of your image (use control net to keep the shapes, colours, details as you want), and the send it back to extras again if you want to upscale it even more.Hit and miss to be honest. But helps me with my 1070 which cant handle much.
Now try mess around with LCM LoRA. Works nice on cartoon characters:
LCM-LoRA: High-speed Stable Diffusion - Stable Diffusion Art
LCM-LoRA can speed up any Stable Diffusion models. It can be used with the Stable Diffusion XL model to generate a 1024x1024 image in as few as 4 steps.
OnlyOneKenobi
Executive Member
- Joined
- Dec 6, 2013
- Messages
- 5,348
- Reaction score
- 7,960
I trained a new LoRA model for the "ghost in the wall" effect which turned out pretty cool - very powerful especially when used in combination with controlnet and the various styles and models that local SD has available.


OnlyOneKenobi
Executive Member
- Joined
- Dec 6, 2013
- Messages
- 5,348
- Reaction score
- 7,960
This was my test :

Each image will probably need some kind of tweaking, but for this particular one, I used the IMG2IMG loopback script, set with 6 loops and denoising at 0.25 - the final denoising strength set to 0,6.
I used ControlNet Openpose and SoftEdge to retain the composition, background details, general shape and pose of "Lara" in the image.
Anyway, I think it turned out pretty good and I'm happy I don't need to shell out money on expensive subscriptions to get the same results as Magnific and similar services.
OnlyOneKenobi
Executive Member
- Joined
- Dec 6, 2013
- Messages
- 5,348
- Reaction score
- 7,960
ControlNet has been updated with a Depth preprocessor that fixes hand issues quite well from my testing. If you have an image where the hands of a subject is messed up, send the image to Inpainting, enable the depth controlnet and select the depth_hand_refiner pre-processor. Then, in the inpainting window, mask the hand or hands of your subject, set the denoising strength high (0.7 and up) if the hand is severely messed up, and then generate.
 github.com
github.com
GitHub - Mikubill/sd-webui-controlnet: WebUI extension for ControlNet
WebUI extension for ControlNet. Contribute to Mikubill/sd-webui-controlnet development by creating an account on GitHub.
github.com
OnlyOneKenobi
Executive Member
- Joined
- Dec 6, 2013
- Messages
- 5,348
- Reaction score
- 7,960
There's been another update to ControlNet to iron out issues with the new FaceID IP Adapter model, which is ridiculously powerful. It can copy the likeness of a face more accurately than the previous ControlNet IP Adapter models, it is a bit more complicated to use, but when done right, the results are amazing.
Be sure to download the LoRAs and the various IPAdapter models as seen in the link below.
 github.com
github.com
Be sure to download the LoRAs and the various IPAdapter models as seen in the link below.
[1.1.428] IP-Adapter FaceID · Mikubill/sd-webui-controlnet · Discussion #2442
IP-Adapter FaceID provides a way to extract only face features from an image and apply it to the generated image. Please follow the guide to try this new feature. Installation of insightface FaceID...
github.com
Does anyone know how to use stable diffusion for NSFW images? i have seen the full guide, seems too hard for me, so will it be better to find a stable diffusion alternative?